Using Message Acknowledgements for Tracking, Correlation and Fire & Forget
This whitepaper looks at how tracking end to end message acknowledgements can improve service reliability for mission critical messaging. This is achieved by enhancing message tracking services and providing information on messages being delivered and read. It then describes how this can be extended to provide a “Fire and Forget” quality service, using operator alerts and guaranteed action points (GAP). The paper also shows how these capabilities are provided in Isode’s M-Switch products.
End to End Acknowledgements and Reliability
When a message is sent between a pair of clients, it is submitted by the sending client to the first MTA (Message Transfer Agent), then switched through a series of MTAs and finally delivered to a mailbox. The receiving client will retrieve the message from the mailbox, and display it to the recipient.
All of the protocols involved in this chain are designed to ensure there is no message loss. In normal operation, this process will work reliably and quickly. However, there are two problems:
- If one of the components in the chain fails, or works incorrectly, a message may be lost, or
- A component in the chain may operate too slowly, causing unacceptable delay.
In order to guard against these problems, end to end acknowledgements must be introduced. It is a basic protocol design requirement, that if you want end to end reliability, you need end to end acknowledgements (see End-To-End Arguments in System Design).
Messaging protocols provide two types of end to end acknowledgements, illustrated above:
- Delivery Report. This is issued when a message is delivered by MTA into mailbox. It is an indication that the message has reliably arrived at its destination. When requested, conformant systems will issue a delivery report, so a missing delivery report is a clear indication of a message being lost or delayed in transit.
- Read Receipt. This is issued when a message is read by the recipient. In SMTP systems, client issue of read receipt is optional (for privacy reasons). This means that read receipts cannot be used to ensure that messages are read unless the receiver is required to send a read receipt when requested.
In this paper “Acknowledgement” is used to mean “Delivery Report or Read Receipt”. The positive versions of these acknowledgements provide end to end confirmation to ensure reliability. Negative versions of these reports are used when errors occur. Negative delivery reports indicate a message delivery failure. Negative read receipts are used in specialized situations, such as the message being deleted before it is read.
M-Switch products are available which support the SMTP protocol family and the X.400 protocol family. These have specific names for each of these types of acknowledgement.
| X.400 | SMTP | |
|---|---|---|
| Delivery Report | DR (Delivery Report) | DSN (Delivery Status Notification) |
| Read Receipt | IPN (Inter-Personal Notification) | MDN (Message Disposition Notification) |
In this paper, the generic terms Delivery Report and Read Receipt are used. A message sender can use delivery reports to be certain that a message has been delivered, and read receipts to be certain that a message has been read.
Operating ‘In the Middle’
M-Switch’s acknowledgement handling works at the MTA level, and so operates in the middle of the path between sender and recipient. This could be close to the sender, close to the recipient, or at the boundary between organizations. This can work in multi-protocol environments, including MIXER conversion between X.400 and SMTP.
The sending client is a logical point to handle acknowledgements, as it is the endpoint for end-to-end reliability. However, a typical system will have clients on many systems, which would make it hard to provide a managed service that monitored each end point. It makes more sense to monitor at a server.
M-Switch provides a number of open standard protocol interfaces, including:
- SMTP Message Transfer (shown in the example above).
- SMTP Message Submission (so that clients can directly submit messages)
- LMTP (RFC 2033) Message Delivery (to an IMAP server such as M-Box)
- X.400 protocols (P1 Transfer and P3 Submission/Delivery) for use in pure X.400 and MIXER environments.
This open standard support makes it straightforward to ‘insert’ M-Switch in the ‘message flow’ to provide the services discussed below. This seems to be a useful architectural flexibility. In the above example, messages are being sent to/from an Exchange based organization and various other organizations including an outsourced Gmail organization. All messages between these organizations pass through M-Switch.
An architectural observation is that once a message has reached M-Switch, all of the services described below are enabled. However, if a message fails to reach the M-Switch server, it will not get recorded. So for maximum reliability, it is best that M-Switch is the submission server. A pragmatic approach will often be to put M-Switch close to the submission server, so that risk of message loss between submission and M-Switch is extremely low.
Tracking, Correlation and Reporting
For each message/recipient pair, M-Switch records the following information in an audit log file:
- Message arrival (submission or transfer in)
- Message departure (delivery or transfer out)
- Delivery report (indicating message delivery or delivery error)
- Read receipt.
Read receipts and delivery reports contain fields that allow them to be correlated unambiguously to the messages to which these relate. This correlation is key to the services provided. Two useful services are:
- Message tracking. This enables an operator to look at selected messages sent, and determine when they left the managed MTA, when they were delivered and when they were read. This is important information in support of a managed service. Note that in order to track message delivery and message reading, it is necessary that the client submitting the original messages request these services.
- Reporting. This enables the analysis of messages over a period, to determine which were correctly delivered and read. These reports are intended to help a service operator prove that Service Level Agreements (SLAs) have been achieved, and that all messages have been correctly delivered in appropriate timescale. Where there are failures, the reports can help diagnose where and why failures occurred, and enable the service operator to make changes to ensure that they do not repeat.
The diagram above shows Isode’s architecture for message tracking, correlation and reporting.
M-Switch records the details of each message and acknowledgement in an Audit Log. The Audit Log consists of structured text records, and is written locally to the M-Switch server to guarantee that all messages and acknowledgements handled are correctly recorded.
The Audit database is an SQL DBMS. There will typically be a single database per site, with feeds from multiple M-Switch servers. For tracking and correlation, it is desirable to have all the information in a single database. For medium and large deployments, the Audit Database is likely to run on a different server to the M-witch servers and management clients. All of the Isode applications use JDBC to access the audit database.
Each M-Switch runs an Audit Log Parsing Daemon, which feeds information to the Audit Database in near real time. Thus the audit database has information on messages and acknowledgements from each M-Switch server. There are two basic arrangements of M-Switch that are supported, that can be used independently or mixed:
- Parallel. In a horizontally scaled deployment, two or more M-Switch servers may be used to achieve reliability and performance. Messages and acknowledgements will go through just one server. The acknowledgements to a message will not necessarily come back through the same server as the message. Tracking needs to work irrespective of the server traversed.
- Sequential. Where a message passes through multiple M-Switch servers, it is important to be able to track its progress through each one.
This architecture gets all information on messages and acknowledgements into a single DBMS, enabling multiple MTAs to be managed from a single point.
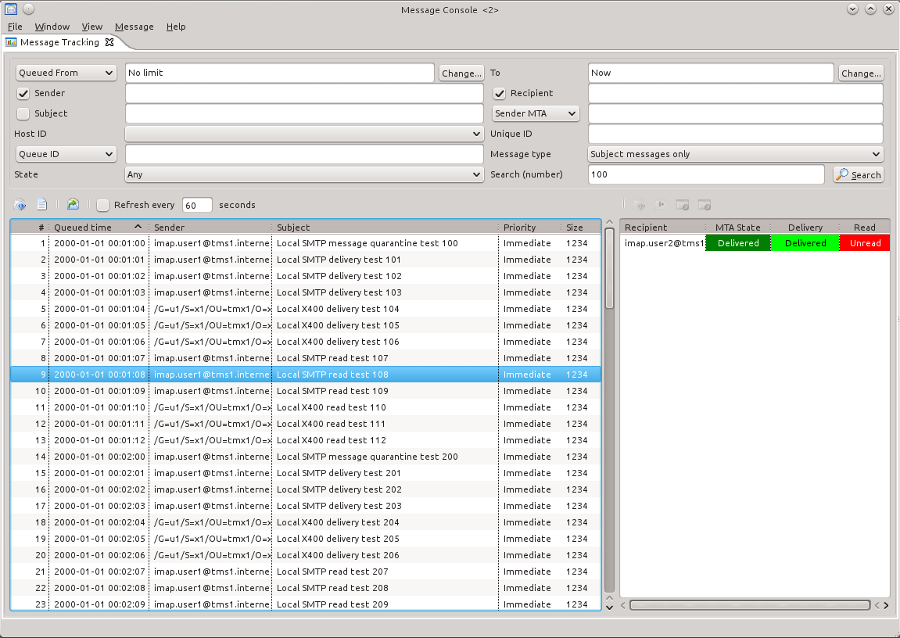
Isode’s MConsole message management GUI connects to the Audit Database using JDBC, and provides a Message Tracking View shown above. MConsole Message Tracking View allows the operator to search for specific messages or class of message using a range of parameters. This tracking view looks for the acknowledgements of a selected message, and so can show to an operator if the message has been delivered or read (where the appropriate acknowledgements have been requested). This shows how the basic correlation works, and how it adds value to the older message tracking system which did not deal with acknowledgements.
Another important capability enabled by an audit database containing records of all messages and associated acknowledgements is to provide a summary report of messages, and how many of them had requested acknowledgements provided. A report of this nature is important in support of providing a high reliability message service. Acknowledgements prove that messages were delivered and/or read. In a correctly functioning service, all reports requested will be present, and the report can show this. This report can be used to show that SLAs have been met. In the event that the report shows that some messages have not been correctly acknowledged. Isode plans to provide this type of report.
Database Reliability
It is important that a tracking and correlation service be reliable, as this is being used in support of high reliability services. There are several levels to consider.
- M-Switch audit logging is done to the local file system as a part of core M-Switch operation, and so reliability is inherent in the design.
- The audit log parsing daemon ensures that all records from the audit logs are recorded in the database exactly once. This is resilient to restarts of M-Switch, Audit Log Parsing Daemon and Audit Database.
- The M-Switch Audit Database services can be provided by two high quality DBMSs:
- Microsoft SQL Server – a widely used commercial DBMS.
- PostgreSQL Server – a widely used open source DBMS.
- The Audit Database can be a single point of failure. Three approaches to mitigate this are :
- Failure of the audit database does not prevent message flow. If an outage of the tracking service is acceptable, a simple approach is to accept this. When the database is restored or replaced, the audit log parsing daemon will ensure that no data is lost from the audit database. This can include replay of historical logs.
- Both supported DBMSs have a multi-master mode to give database reliability. Audit Log Parsing Daemon and MConsole support this, by allowing failover between servers. This removes the single point of failure.
- Two independent Audit Databases can be established, with each M-Switch in the managed system feeding logs into both audit databases. This gives a system without a single database point of failure that does not rely on database replication capabilities.
Fire and Forget
The term “fire and forget” is used in the description of a messaging system where the sender can send a message and be confident that it will be appropriately delivered and read, without any subsequent user action (such as checking for acknowledgements or errors). The model is that of a military officer writing and order and handing it out to be sent, confident that it will be delivered to the action recipients who will act on it.
Systems built to support fire and forget work in different ways, as this is a high level concept rather than a detailed operational approach. Isode’s approach is to use the tracking capability to detect two situations:
- A message is sent, and an error is returned,
- A message is sent with acknowledgement requested, and the acknowledgements (delivery and/or read receipt) are not received in a timely manner.
If neither of these occur, it is reasonable to infer that the message has been correctly handled and that no action is needed. In the event that one of these does occur, M-Switch enables sender-independent actions to be taken to meet the fire and forget target.
Requested acknowledgements are allowed to flow back to the sender, so the sender may also take action in error situations.
Detecting Missing Acknowledgements and Errors
When a message delivery (or read) error occurs a negative acknowledgement will be sent. This is a clear event recorded in the audit database that is straightforward to recognize.
Where an acknowledgement has been requested and not received, four situations are possible:
- The action associated with the acknowledgement (message delivery or message read) has not happened, due to message loss or other catastrophic error.
- The action has happened, but an acknowledgement was not sent.
- An acknowledgement has been sent, but has been lost.
- The action has not happened due to delay.
The tracking system can tell that an acknowledgement has not been received but cannot distinguish between these four situations. It is essential to deal with the first. It is also important to deal with the last situation after an appropriate period of time, as the timeliness is an important aspect of fire and forget.
Isode enables configuration of a time values after which the delay associated with a missing acknowledgement is considered to be an error. These time values are separately configurable for:
- Delivery Acknowledgements and Read Acknowledgements, as generally more time will be allowed for message read than message delivery.
- Priority, both civil (Normal/Urgent/Non-Urgent) and military (OVERRIDE, FLASH, IMMEDIATE, PRIORITY, ROUTINE, DEFERRED). Higher priority messages will generally have shorter times, in part because they tend to be time critical, and in part because the overhead of investigating messages which are just delayed is more justifiable for higher priority messages.
Isode uses this configuration in two places. The first of these is an acknowledgement view in MConsole, shown below:
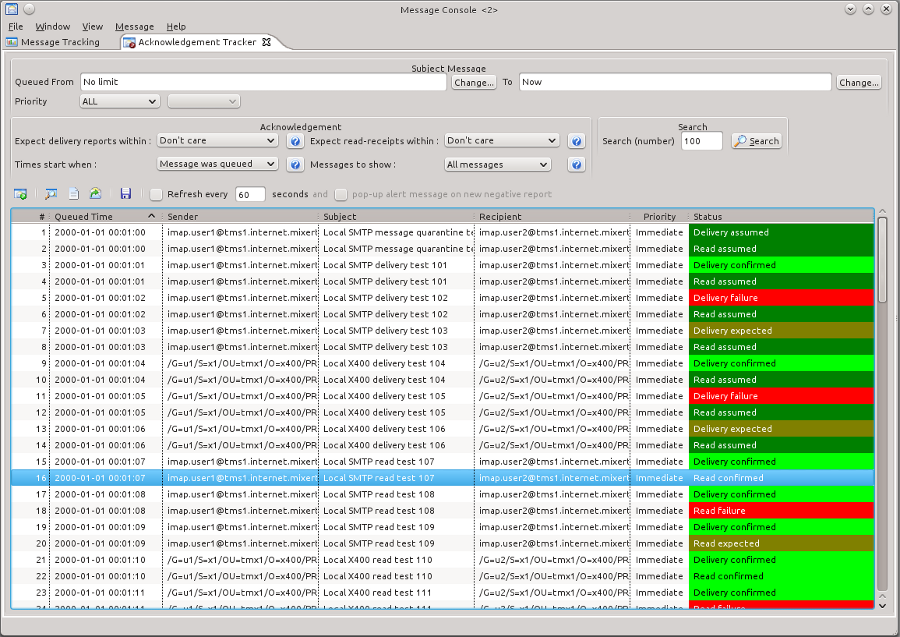
This screenshot shows a mix of X.400 and SMTP traffic. With delivery reports and read receipts. Four colours are use:
- Pale green shows where a message has been acknowledged.
- Dark green shows where no acknowledgement has been requested and none received, so that correct handling is inferred.
- Bright red is where there is an explicit failure.
- Dark red is where an acknowledgement has been requested, and has not been received in the expected time.
In normal operation, the green lines would be filtered out, so that the operator is only shown messages where there are problems.
Acknowledgement view enables tracking of acknowledgements in a flexible manner. It is normally used to look at error situations (missing acknowledgements and negative acknowledgements), although it can be used for any combination. It will commonly be used either for delivery reports only or for both delivery reports and read receipts, although other combinations can be configured. This view works by searching for messages in the audit database and then matching correlation information.
This view can be configured to refresh automatically, enabling an operator to actively monitor for new problem situations (errors such as non-delivery, or an acknowledgement not arriving within the expected time). This mode also has efficient database use, as it only needs to look at message and acknowledgements that have occurred since the last refresh.
Handling Errors
The capability shown above illustrates how errors can be detected and presented to an operator who is pro-actively watching the acknowledgement view screen. Most deployments will not have this level of operator support, and a more automated approach to handling errors is desirable.
An ‘obvious’ approach to handling an error is to simply resend the message. Experience has shown that this is generally a very poor approach. For example, if the problem is message congestion, resending the message will simply increase congestion. Essentially there is high risk that the resent message will hit the same problem as the first message. There needs to be an approach which either leads to investigating the problem or handling the message in a different manner. M-Switch provides two approaches which are described in the following sections:
- Operator Alert.
- Alternate Recipient (Guaranteed Action Point).
Operator Alert
Many systems requiring fire and forget support will have operator cover, although it is unlikely to be dedicated to dealing with message tracking and fire and forget support. The basic model with operator alert is to provide a mechanism to alert the operator that there are message error situations that need handling. The operator can then go to MConsole acknowledgement view to find out details and subsequently investigate the problems. The following alerting mechanisms are provided:
- Email, with a simple summary of the problem or set of problems.
- Windows Event or Unix Syslog, that can be sent to a management system.
This provides flexibility for a range of operating environments. An example email alert is shown here:
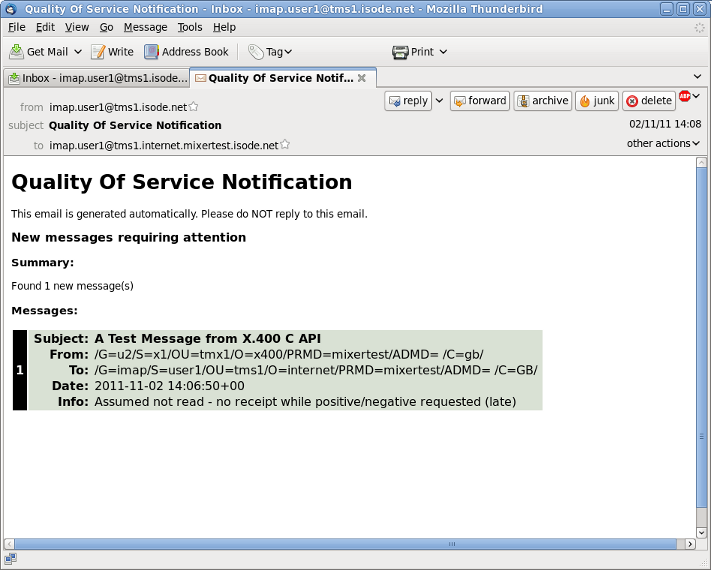
Operator Alerts are provided by the M-Switch QoS Daemon. The QoS Daemon monitors the audit database in exactly the same way as Acknowledgement View, so that it can send operator alerts on negative and missing acknowledgements.
Alternate Recipient/Guaranteed Action Point
A second approach is to send the original message on to a different recipient, along with information about the problem noted (non-delivery or acknowledgement delay). Unlike the operator, this recipient does not need to have any knowledge of message tracking. The (new) recipient simply needs to act on the message to ensure that the sender’s intended actions are carried out. This could be a variety of actions from picking up the phone to following the instructions in the message. The clear advantage of sending the message to a human recipient is flexibility of response.
In some systems, this new recipient is termed “guaranteed action point”, as it will be configured to be a mailbox that has managed cover and can be expected to deal with a message in all situations. Another description is simply “alternate recipient”.
A simple configuration setup is to have a single configurable alternate recipient. For X.400, the sender specified alternate recipient may be used, but there is no equivalent in SMTP. A more complex approach would be to determine the recipient based on rules relating to message sender and recipient.
M-Switch supports Guaranteed Action Point for SMTP messages.
Alertable Missing Acknowledgement
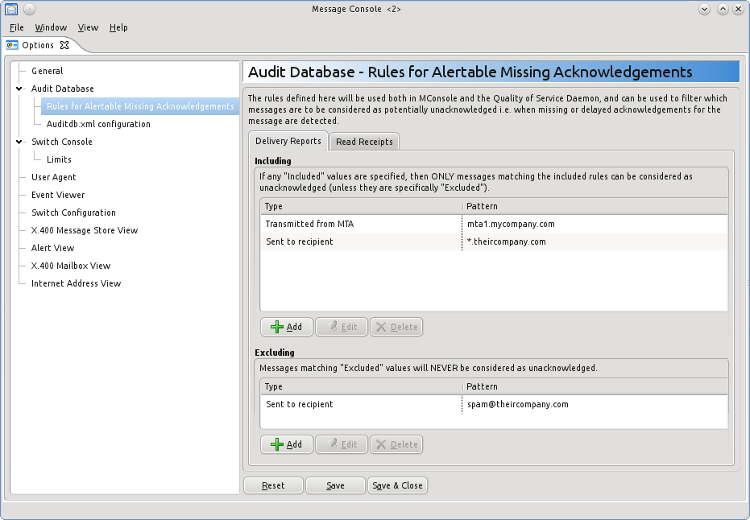
For some messages, acknowledgements may not be sent. This may simply be because they are not supported. This should not be the case for delivery reports (but in practice it happens for some recipients) and often happens for read receipts, as many clients (particularly SMTP) do not support them. Many SMTP clients also make read receipts a user choice (for privacy reasons) so they will not be consistently sent and cannot be relied on. In environments where it is important to ensure messages are read, read receipts must be mandatory.
To support environments where there is partial support, alertable missing acknowledgements enable configuration of lists of recipients (based on full or partial address match) for which delayed acknowledgements will not be treated as errors (delivery reports or read receipts configured separately).
Conclusions
This paper has described Isode’s message tracking and fire and forget capabilities. Most of these are available in M-Switch R15.1. Statistical reports will be added in a future release.
Whitepaper Licensing
Isode whitepapers are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License
![]()
Browse Related Whitepapers
