Sending FLASH Messages Quickly: Techniques for Low Latency Message Switching and Precedence Handling
Military Messaging systems, and other messaging systems with time critical operational requirements such as Aviation (AMHS), require that high precedence messages are submitted, transferred and delivered very quickly. In this paper we look at how messages can be handled to achieve message switching times of a few hundred milli-seconds, for both low and high volumes of traffic. The importance of Permanent Associations as a way of avoiding delays in opening a connection is described and consideration is given to Precedence Handling, describing techniques that ensure high precedence traffic gets optimum (low) latency. The paper explains why message pre-emption is not a useful approach and why DiffServ is important when there are bandwidth limitations.
Throughput and Latency
Message throughput is the rate at which a system can transfer (or submit or deliver) messages. Message throughput is often measured in “half messages per second”, which is the number of messages coming into or out of the queue. Latency is the time taken to transfer a message, from arrival until departure.
Typically, a commercial message system will consider throughput as the primary measure of performance, as the number of messages you can process is the most significant consideration. This paper considers optimizations for low latency. Many things that you do in order to process messages quickly will also help in improving throughput and latency. Other activities lead to a trade-off, where processing to reduce latency will increase processing cost and reduce throughput.
Throughput can also be measured in time. For example a message switching twenty messages per second (half messages in and out) would have an average throughput of a message every 50 milli-seconds. This figure can sometimes be confused with or mis-represented as latency.
Because messages are switched in parallel, latency will higher than throughput (both measured in time per message). Average (mean) latency for an operational system will typically be a lot higher, because of the small percentage of messages that get queued for an extended period due to remote system unavailability. Latency is generally best measured by median value, or appropriate percentile values (e.g., 95%).
Product & Queue Considerations for Low Latency
There are a number of things that can be done to help achieve low latency, primarily these are Message Switch (MTA) consideration although some are also relevant for Message Stores. All except the last are things that will make the MTA go fast and will consequently also improve throughput:
- Careful engineering. To optimize performance, substantial care must be taken with product design and implementation.
- Simple disk use. An MTA will typically receive a message, write it to disk (to secure it), send it on and then delete it. As a consequence there is an inherent demanding disk i/o requirement, and it is important to optimize this.
- Connection and process re-use. Connection open/close and process start/stop are quite expensive and should be minimized.
- An event driven system that avoids queue scanning is preferable.
- Alternate routing so that transfer to a fallback peer MTA can be used in the event of primary peer MTA failure. This will avoid delays due to MTA failure.
- Load balancing between multiple peer MTAs may be helpful to minimize latency.
- Don’t try to do too much. At some point, trying to do too much will not be effective. Under high load, an MTA should optimize its work rate and avoid trying to do too much and start thrashing.
- Try to do things quickly. In order to get low latency, things should be scheduled to happen quickly. This can cost resource, and may conflict with goals 3 and 7. An effective approach needs to be carefully balanced between these considerations, especially under high load.
If followed carefully, this list will lead to an MTA that produces fairly low latency.
The time taken to transfer a small message will typically be 100-200 milli-seconds. The time taken to open a connection will generally be at least 300-500 milli-seconds, and in many situations may be over a second or even several seconds. Where no connection is open, message transfer latency will be limited by the time to open a connection. For many deployments, this additional delay due to connection establishment does not matter; in this next section we consider how to avoid this delay in situations where it does.
There are two primary factors determining time to establish an X.400 association.
- The first is work to start processes and perform authentication. This is platform and product dependent. For Isode M-Switch X.400 , it would typically be 200-500 milli-seconds.
- The second is the time for three “round trips” due to protocol handshakes. On a typical wide area Internet connection the round trip time might be 200 milli-seconds.
It can be seen that the delay due to connection startup is of particular concern in higher latency environments.
Once a connection is established, there are no handshakes for small messages and so no need to wait for any further protocol handshakes. There is a handshake at the end of message transfer which may slightly delay start of transfer of the next message. For larger messages, there is a windowing mechanism, which should have parameters chosen so that there is no latency impact on message transfer. Once a connection is established, X.400 P1 is good for high latency connections (substantially superior to “chatty” protocols such as SMTP).
Permanent Associations
The way to avoid the delay caused by opening a connection is simple: make sure that the connection is open when the message arrives. Two techniques are suitable:
- Configure permanent associations (connections). The MTA will open connections to selected peer MTAs and keep them open. This is the most effective approach, and will guarantee an open connection.
- Keep connections open for a period after message transfer (slow close). This can be used to keep connections open for peer MTAs with moderate load. It avoids the configuration overhead for permanent associations. For some connectivity and traffic patterns this can be very effective.
Isode recommendation is that if you want to have low latency, that use of permanent associations is the best approach.
Precedence Handling
Environments with requirements for low latency usually also have a model of message precedence (priority). X.400, unlike internet messaging, has a three level message priority specification:
- Urgent
- Normal
- Non-Urgent
STANAG 4406 military messaging, which is based on X.400, extends this to six levels:
- Override
- Flash
- Immediate
- Priority
- Routine
- Deferred
Military messaging deployments generally have more stringent delivery timing goals for higher precedence messages, and also usually set lower size limits (so higher precedence messages are generally smaller). A standard requirement is that handling of lower precedence messages should not get in the way of handling higher precedence messages.
In order to support this, precedence (priority) must be considered in the scheduling algorithms. These must work so that higher precedence messages are always handled first, and lower precedence messages are only handled when this does not get in the way of handling higher precedence messages.
It is also important for an MTA to reserve capacity for higher precedence messages only. This means that under high load, the MTA will refuse lower precedence messages before it reaches maximum processing capacity, so that it will always be in a position to accept higher precedence messages.
Permanent associations can also be used very effectively in conjunction with precedence handling, by reserving permanent associations for a specific level of message precedence. For example, one or more permanent associations can be configured for Flash (and Override) messages only. Lower precedence messages can use a separate permanent association, or open a connection on demand. The higher priority association(s) are ready to transfer Flash messages.
Why Message Pre-Emption is (usually) a Bad Approach
Message pre-emption is a technique that has been advocated to optimize latency of higher precedence messages. The idea is that if a higher precedence message needs to be sent to a peer MTA and a lower precedence message is being transferred, then the transfer of the lower precedence message should be stopped. Superficially, this seems a good idea, but in practice does not help. There are a number of reasons:
- A typical message will be transferred in a few hundred milli-seconds, so there is little benefit to stopping its transfer.
- Stopping an X.400 transfer will mean closing the connection, which is undesirable, as discussed above.
- Message transfer is usually constrained by connection latency. That is to say, the end to end protocol handshakes are the limit to message transfer and there is ample network bandwidth. This means that stopping transfer of a lower precedence message will not help with transfer of the higher precedence at all.
These reasons mean that in the majority of situations message pre-emption will not help. Of course there are situations with large messages going over a slow link where there will be some bandwidth constraint. In such a scenario, message pre-emption would help.
In general, an MTA cannot tell whether or not pre-emption would help. A brute force approach would be to use pre-emption in all cases, to ensure that higher precedence messages get the best possible latency. In a high load situation this could seriously impact latency of lower precedence messages without helping higher precedence messages at all. Fortunately, there is a better approach for dealing with bandwidth constraint, described in the next section.
Dealing with Bandwidth Constraint
When does Bandwidth Constraint Occur?
In a modern network architecture, computers are rarely connected directly to a wide area network. The diagram that follows shows a typical wide area network configuration. At one end, a computer is connected via a Local Area Network (LAN). At the other, a single PC is connected by a “stub” LAN to a router. Computers are typically connected to fast LANs, and congestion normally occurs in a network segment between a pair of routers that may be several network hops away from the end points.
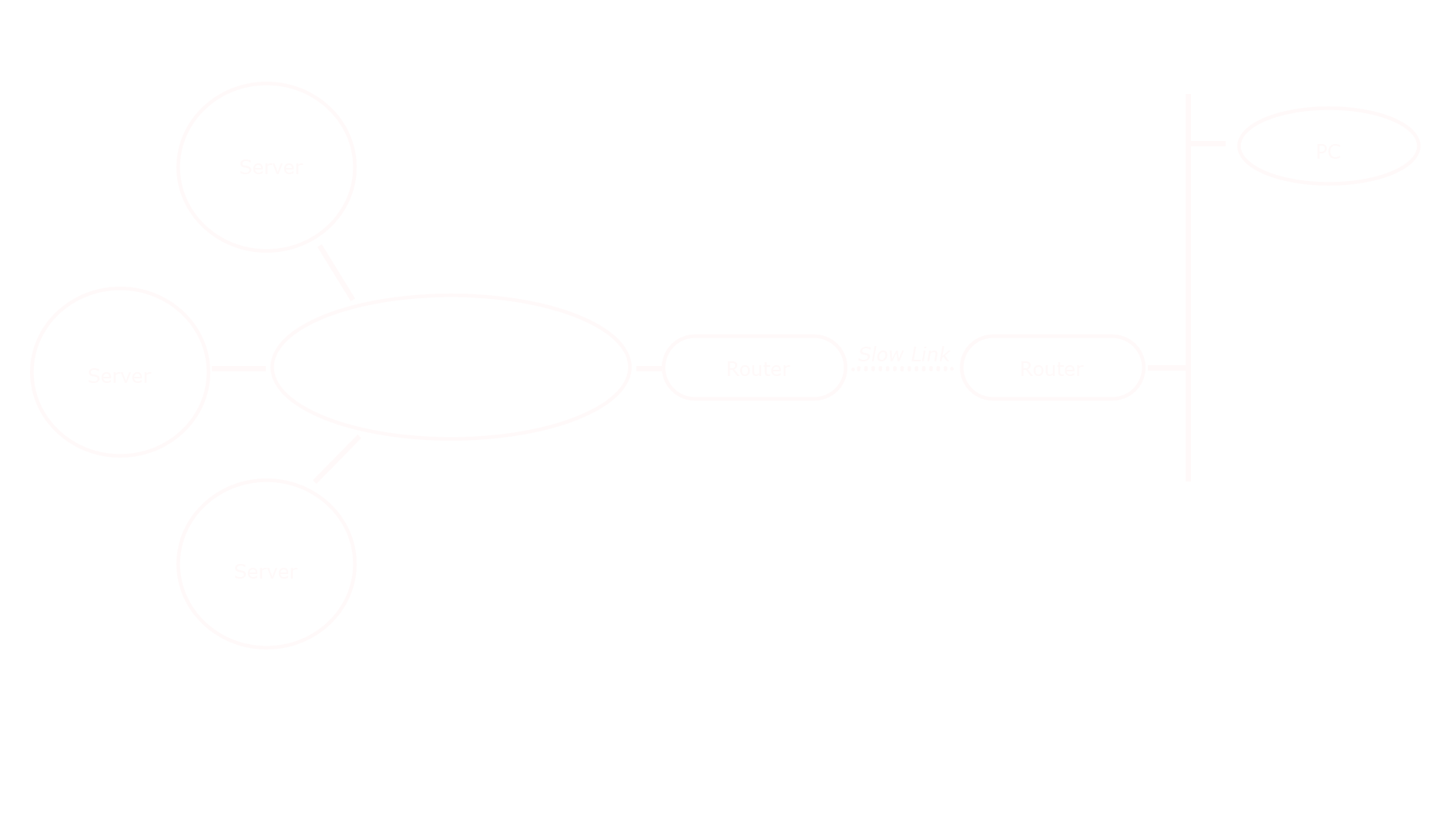
Bandwidth constraint will happen when a network segment gets congested, and this will prevent data from being transferred at maximum speed. In most congestion situations, the end computer will not be directly aware that it is happening, or what the cause is.
Why TCP Works
In order to understand the approaches described below, it is useful to understand some key principles of how TCP and the Internet works. The basic model of an IP network is that a router can drop packets if it is unable to forward them; the IP part of TCP/IP is unreliable and this is a key part of the architecture. When congestion occurs, a router may drop packets.
TCP reacts to packet loss by slowing down – decreasing the rate of sending packets and “closing up” the acknowledgement window. A consequence of this behavior is that as a router starts to drop packets, TCP based applications will slow down and so the traffic load will be reduced. This will remove the congestion and the need to drop packets. TCP behaves in a friendly manner, leading to preventing congestion. This mechanism is central to why the Internet works.
Using DiffServ & Precedence
The basic TCP model above has all TCP connections as equal, and congestion will hit all users of a congested link in the same way. The goal with precedence handling is to give preference to higher precedence messages. This can be achieved with a technique known as Weighted Random Early Drop (WRED). RED, on which WRED is based is considered as fair mechanism for choosing which IP packets to drop. WRED makes it unfair again, by selectively dropping packets based on IP packet classification.
IP packets may be labelled by a five level precedence (Override; Flash; Immediate; Priority; Routine), which corresponds exactly to the five top levels of STANAG 4406 message precedence (deferred is missing). This precedence information is represented in the TOS (Type of Service) byte of the IP packet. General handling of this TOS byte is specified in a set of standards known collectively as Differentiated Services or “DiffServ”. DiffServ specifies a framework for Per Hop Behaviours (PHBs).The default PHB is to handle packets based on use of IP precedence.
In simple terms, using the DiffServ default PHB with WRED will lead to lower precedence packets being selectively dropped. When congestion occurs, this selective packet dropping will cause the lower precedence TCP connections to slow down, without affecting the higher precedence connections.
In order to make all of this work, two things are needed:
- Build the network using routers that support the DiffServ default PHB with WRED.
- Send IP packets with precedence to match the precedence of the message being transmitted. This is the key implementation consideration for the MTA, which involves managing connections of different precedence.
This scheme will work nicely for messages being sent between a pair of MTAs, throttling back lower precedence messages in the event that congestion occurs. This gives all of the benefits of pre-emption and none of the disadvantages.
More importantly, this scheme will also interact correctly with messages being sent between different MTAs but sharing the same congested link. Similarly, it will deal with congestion between multiple applications. These are major benefits of this approach.
STANAG 4406 Annex E and Very Slow Networks
The previous discussions apply primarily to fast and medium speed networks. When very slow speeds are being used (9600 baud or less), it is appropriate to use a different set of protocols. STANAG 4406 Annex E has been designed for low bandwidth and in particular HF radio. This is described in the Isode White Paper Messaging protocols for HF radio.
STANAG 4406 Annex E is also appropriate for use in situations (at low and high bandwidth) where the recipient is in EMCON (Emission Control) and cannot send out radio or satellite signals.
STANAG 4406 Annex E and the associated ACP 142 and STANAG 5066 protocols have a strong model of precedence. In particular, packets associated with higher precedence messages will always be sent first, and this gives a natural and automatic precedence handling when these protocols are used.
Isode Product Support
These general techniques could be implemented in any product. All of the recommended techniques are implemented by Isode’s M-Switch X.400 product.
Conclusions
This paper has described a number of techniques for providing low latency message switching, and for precedence handling. Two are of particular note:
- Permanent associations are critical if message switching latency of a few hundred milli-seconds is to be achieved.
- DiffServ based precedence handling is an important technique for ensuring best precedence handling in a bandwidth constrained network.
Whitepaper Licensing
Isode whitepapers are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License
![]()
Browse Related Whitepapers
