M-Vault Failover & Disaster Recovery
This whitepaper looks at how Isode’s M-Vault directory server provides failover capabilities in support of disaster recovery using a single master approach. It looks at requirements for replication, and describes the architecture of Isode’s approach and how this addresses disaster recovery requirements.
M-Vault also supports a multi-master approach which is described in the whitepaper [ACID Multi-Master Replication in M-Vault Directory].
Why Replicate Directories?
Many services using LDAP and X.500 directory servers are highly replicated. Reasons for this include:
- Performance of read and search. By replicating data onto multiple servers, read and search capacity can be increased.
- High Availability. Service availability is not dependent on a single server.
- Locality of Access. Where directory users are in multiple locations, replication allows (fast) access to local servers. This can be particularly important if network communication between locations is constrained.
- Partition. Directory replication allows data to be copied into systems that may be partitioned, enabling independent operation.
- Security Boundaries. Directory replication allows security boundaries to be maintained, where client access is not permitted across the boundary.
- Survivability. Directory replication helps to build survivable systems.
Directory services are often used to hold mission critical data, and replication is key to such deployments.
Single Master vs Multi-Master
There are two basic strategies to dealing with write access (data modification) in a directory:
- Single master. Where all changes are made to a single server (the master).
- Multi-master. Where changes may be made to one of several servers.
There are scenarios where multi-master is preferable, and others where single master is best. This paper looks at scenarios where single master is preferable and describes Isode’s M-Vault approach to supporting single master.
M-Vault also support multi-master. The benefits of multi-master and the approaches taken in M-Vault to support multi-master are described in the Isode white paper [ACID Multi-Master Replication in M-Vault Directory].
The Benefits of Single Master
Single master has a number of distinct advantages:
- There is definitive state. The data in the master server is authoritative, whereas in multi-master, the state depends on multiple servers, and cannot generally be determined.
- Client update is definitive. A related characteristic is that when a directory client makes a change to the directory, it knows that it has been made. For multi-master, a change may be overridden by a change made in another server. This can have bad effects for some data, such as system configuration.
- Complexities of conflict resolution avoided. Dealing with conflicting directory updates can be complex, and there needs to be an approach for dealing with directory updates that are rejected. The consequences of rejects can be awkward, particularly where multiple related changes are made, and one gets failed due to conflict.
- Efficient network use. Single master replication is much simpler and more robust than multi-master. This can be particularly important when operating over constrained networks.
- Efficient update. Replication gives natural performance gains for read and search. If updates are made on multiple servers, the individual updates still need to be made on each server and conflict resolution needs to be done in addition. This means that for large directories, multi-master systems will generally be operated as if they were single master, so that most updates are applied to one server and conflict resolution is minimized.
- X.500 DISP can be used. The only open standard for directory replication is X.500 DISP (Directory Information Shadowing Protocol). All multi-master protocols are proprietary. So single master is essential if you want to have open standard multi-vendor replication.
In Isode’s experience, single master is a good choice for many directory deployments, and strongly preferable in some situations.
Requirements in the Event of Master Failure
A key question for a single master architecture is “what if the master fails?”
For many directory deployments, including those with extremely high requirements for read/search availability, requirements for availability to make updates (write availability) are lower. It is possible to make the master directory of a single master directory server have very high availability, using for example:
- RAID disks.
- Clustered server (to deal with server or processor failure).
- Independent power supplies and network connections.
With modern hardware, very high availability can be achieved, with modest scheduled downtime for software and hardware updates. It is usually straightforward to provide the level of write availability needed for most directory services.
The scenario that this cannot address is catastrophic system failure and in particular site destruction (9/11 scenario). While such situations may be very unlikely, they must be considered in mission critical deployments.
Isode’s disaster recovery approach assumes unskilled operator support. In order to fail over to a new master directory in a disaster situation, an operator, who may be remote from the site where the master has failed, needs to make the decision that a catastrophic failure of the primary master server has occurred, and that switch to a failover system is necessary. Making this detection automatically is hard, and an attempt to do so would likely cause more problems than it solves. It is important that switchover is very easy, as skilled staff may not be available at the time switchover is required.
The M-Vault Failover Architecture
The basic failover architecture is shown below. In addition the (primary) master server, there are one or more mirror servers. These can be considered as exact “clones” of the master, which are kept up to date with all changes made to the master.

All configuration data for an M-Vault server is held in a cn=config subtree of the directory, and it is this data (along with user data) that is replicated from the master to the mirrors using X.500 DISP. This means that each server in the failover group has identical configuration information. This means that one of the mirrors can always take over as the master. In the event of the master failing, one of the mirrors becomes the new master and it will then take updates and supply updates to any remaining mirrors.
The mirrors also act as “normal” shadow directory servers and can handle read and search operations. So a simple failover configuration would have two servers. In normal operation, the second server would simply operate as a shadow, but it can also take over as master in the event of the primary server failing.

M-Vault Console, the management GUI for M-Vault can be used to manage a failover group of M-Vault servers from multiple locations. M-Vault Console will connect to each of the servers in the failover group, and monitor the status of each server. This will give the operator a view of the status of all of the servers and ability to control failover. Two options to control failover are provided:
- Managed. If the master is available M-Vault Console can tell the master to switch to a server. The current master will complete outstanding operations, and then switch all the servers. This will give a clean switch of master to a new server.
- Forced. If the master is not available, M-Vault Console can tell all of the remaining servers in the group which of them is the new master, and each server will switch immediately. This model is used in a disaster recovery situation, when the master has failed.

The M-Vault failover architecture also supports standard shadowing using X.500 DISP to other directory servers. In a highly replicated architecture the master may shadow to multiple servers, which in turn may shadow to other servers (secondary shadowing). This shadowing needs to continue in the event of failover.
The diagram above shows how this works. When failover occurs, the shadowing agreements move from the original master to the new master. The new master will continue to update the shadow servers. In most cases, this switchover will be transparent to the shadow server.
The M-Vault Console GUI makes it straightforward to restore normal operation after failure of the original master server. When the original server comes back, it will appear to be a second master. M-Vault Console can switch it to being a mirror, and then it will be updated by the new primary master.
If the original master is recoverable, care should be taken to restore service, as updates may have been applied to this master which did not propagate to the new primary master before it failed. Such changes may be identified by inspection of the server logs, and action taken if needed.
Connections between servers in the failover group use X.500 DISP. Authentication can be ‘name only’, ‘simple’ (password based) or ‘strong’ (PKI based). Isode recommends use of strong authentication, as this provides good security.
To support strong authentication for failover, each server has two identities: the failover group and the individual server. Both of these identities are represented in the X.509 Certificates issues to a failover server (one as the SubjectName and one as a SubjectAltName), enabling the failover group name to be used for authentication with shadow servers (enabling failover between members of the failover group) and server name to be used for strong authentication within the server group.
Failover and Recovery in Practice
This section provides some screenshots to illustrate how failover works in practice with M-Vault Console (the M-Vault management GUI).
This first screenshot shows M-Vault Console failover configuration, after initial failover configuration has been set up. A failover group has a configured group identity, which is used as the ‘DSA Name’ when communicating with servers not in the failover group. Each DSA has its own name, and each member of the failover group knows which member of the group is the master. Here we show DSA 1, which is the master.
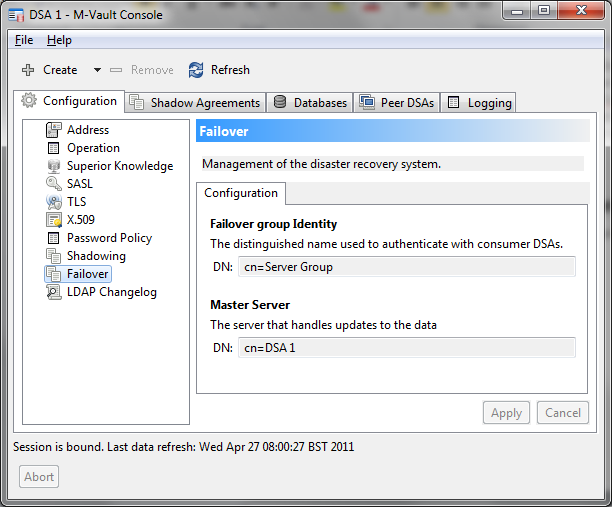
Once an initial directory server is setup and is configured for failover, M-Vault Console enables easy creation of mirror servers, using the configuration of the master server.
Below we can see that a configuration has been set up with three DSAs as members of a failover group, and a fourth DSA shadowing data from the failover group. As shown on the left of the screenshot, M-Vault Console can monitor all of these servers as ‘normal’ servers. There is a special view of monitoring and managing the failover group (on the right), which shows all managed failover groups, and clearly indicates which server is the master. This view shows status of the group and of each individual server. In a real deployment each DSA would be on a different host and not all running on the same host.
The failover view can be used to change the master server, by simple drop down selection. This could be used to migrate a master to a new server and then decommission the old master.
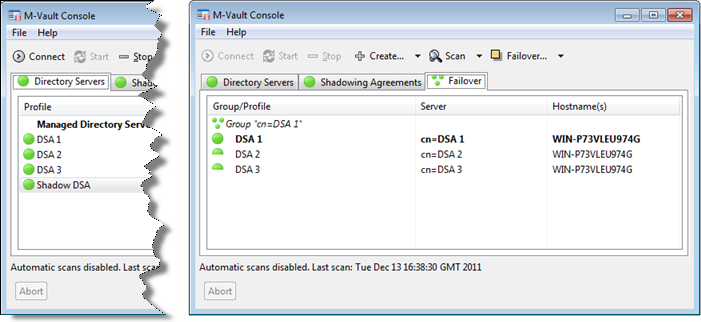
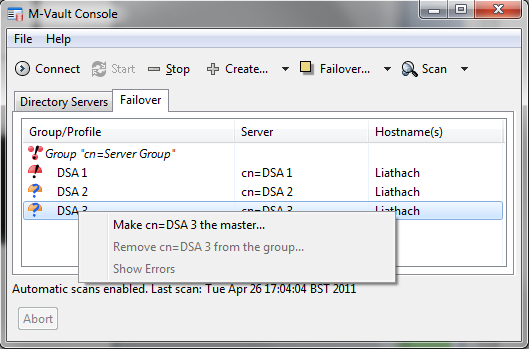
In the next screenshot (below) the master (DSA 1) has failed. DSA 1 is red, as it is not running, and the failover group is in red, as it is not operating correctly. DSA 2 and DSA 3 are shown in orange, indicating that although the servers are running, there is a configuration error with the server group.
If DSA 1 cannot be recovered (a Distaster Recovery scenario), one of the other members of the failover group can be made master, as shown.
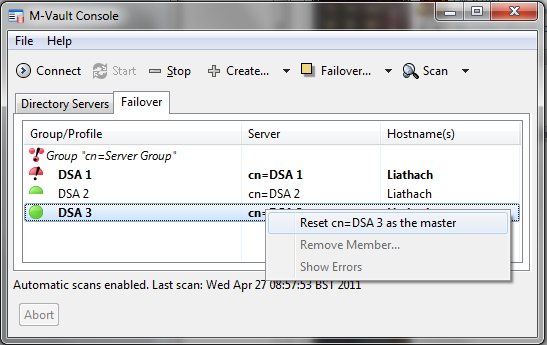
After DSA 3 has been made master (below), DSA 2 and DSA 3 are now operating as a correct failover group and DSA 1 is not operational. A viable configuration has been restored.
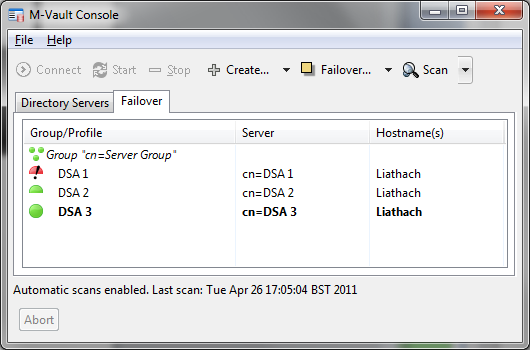
In the screenshot below DSA 1 is restored. As it believes it is the master, failover group inconsistency has been flagged. The screenshot shows how an operator can direct DSA 3 to be the master, which will lead to restoration of a consistent failover group as shown in an earlier screenshot but with DSA 3 as master.
Conclusions
This white paper has shown how M-Vault’s failover master approach enables the benefits of a single master replicated directory to be achieved, while enabling failover and disaster recovery. This is a good approach for some deployments. For other deployments, M-Vault multi-master may be preferable.
Whitepaper Licensing
Isode whitepapers are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License
![]()
Browse Related Whitepapers
