Testing STANAG 4406 Military Messaging over IP Differentiated Services
IP Differentiated Services (DiffServ) is a standardized Internet approach for dealing with different classes of traffic. Isode has added support for differentiated services to its M-Switch X.400 product, so that its priority handling (which supports standard X.400 three level priority, and the STANAG 4406 military messaging six level priority) can utilize differentiated services at the IP level. Isode and NATO staff put together a setup to test military messaging in conjunction with DiffServ, and ran tests on two days in August and November 2007. This paper describes the tests that were done and analyses the results.
The goal of this support is to enable higher precedence messages to get preferential service at the network level, and to better meet the goals of military messaging users. The theoretical case is argued in the Isode whitepaper [Sending FLASH Messages Quickly: Techniques for Low Latency Message Switching and Precedence Handling].
A basic goal of the tests is to validate the theoretical arguments for the benefits of using differentiated services in support of STANAG 4406 messaging, which was achieved. A broader goal was to use STANAG 4406 as an example application to look more broadly at deployment of differentiated services to support a mix of applications.
Background
IP Differentiated Services
IP Differentiated Services are specified in RFC 1274 and RFC 1275. The key functionality of DiffServ is to mark IP (Internet Protocol) packets with a Differentiated Services Code Point (DSCP). The DSCP has standardized values that can be used with IPv4 or IPv6 (with different encodings for each IP version). DSCP values may be set be the originating system, and may be set, modified or interpreted by routers switching the IP packets.
The reason for use of the DSCP is to provide a Quality of Service (QoS) mechanism, so that different types of traffic can be handled in different ways. For example:
- Real time traffic (e.g., video) can be put at the front of the queue, and if packets cannot be processed quickly they are dropped rather than be sent with a delay.
- Where a decision is made to drop packets, packets of lower priority are dropped in preference to those of higher priority.
The key point is that DSCP gives IP routers a framework to understand the required QoS for a packet or stream of packets and make appropriate decisions. This handling can be ‘fine tuning’ to optimize behavior for specific classes of application (e.g., Streaming Video) or it can be a mechanism to deal with situations where a network link simply does not have enough capacity to deal with all of the applications that are attempting to use it.
STANAG 4406 & Differentiated Services
Timely delivery is of particular importance for military messaging, which defines a six level precedence scheme in STANAG 4406 (Override; Flash; Immediate; Priority; Routine; Deferred) which is an extension of the X.400 three level priority scheme (Urgent; Normal; Non-urgent). This application level precedence enables processing and queuing priority to be given to higher precedence messages. DiffServ allows this application level precedence to be reflected at the network (IP) level. Where there is network delay or congestion, this approach will enable appropriate priority to be given at the IP level.
The theory of the benefit that can be gained by STANAG 4406 and other X.400 based messaging from use of DiffServ is set out in the Isode whitepaper [Sending FLASH Messages Quickly: Techniques for Low Latency Message Switching and Precedence Handling]. The paper argues that in most situations message switching performance is constrained by network latency (and not network bandwidth). In situations where there is network congestion, DiffServ is an ideal approach, as it handles message traffic from multiple sources and also can handle messaging packets in the context of traffic from other applications, which may also have associated priority.
Interaction with Other Applications
Network traffic will come from many applications other than military messaging, some of which have very different traffic characteristics at the IP level (e.g., Voice). Handling of DiffServ needs to deal with the complete traffic mix, and then handle message precedence in the context of this. A clear goal of the testing was to examine messaging use of DiffServ in the context of other applications.
Test Framework
Participants
Tests were performed at NATO C3 Agency in The Hague by members of the Communication and Information systems division (CISD) together with Isode staff. NATO’s CISD staff have collected years of experience on Quality of Service through several projects involving Intserv and Diffserv in different projects within test labs but also have real life experience on QoS on existing Coalition Network deployed at ISAF, which is also reproduced at NC3A labs.
Network Setup
The NATO test network was used, with the relevant pieces having the following topology:
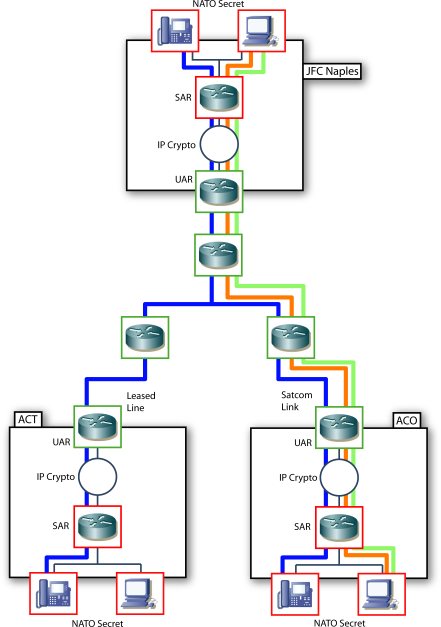
This network represents three NATO Sites (ACO; ACT; JFC Naples) interconnected by a wide area IP Network. The local sites connect local systems with a local router (Service Access Router (SAR)) that uses IP Crypto to connect to an Unclassified Access Router (UAR) that links to the wide area network.
This setup was designed as a general purpose three node network, to enable testing a mix of applications with different QoS levels. A dummy background load was used to stress the network throughput. The intent was to monitor the behavior of X400 messaging in a quite complex mix of topologies and applications. The traffic types were labeled at Best Effort (CS0 or BE) Class selector 1 (CS1), Class Selector 2 (CS2) or Expedited Forwarding (EF).
As experience was gained with running tests, we moved towards making things as simpler and simpler. It turned out to be important to keep test configurations as simple as possible, so that the effects of changing a parameter could be cleanly interpreted. Tests were run with messaging and dummy load traffic going from JFC Naples to ACT.
Messaging Application Setup

The above diagram shows a simplified view of the messaging configuration. Messages are submitted using Isode’s XUXA, which is a test/demonstration STANAG 4406 messaging client. This client was able to set the STANAG 4406 precedence for each message (Deferred; Routine; Priority; Immediate; Flash; Override), and to select from a set of canned messages to enable messages of various sizes (1 kByte; 10 kByte; 100 kByte; 1 MByte; 10 MByte) to be sent. A key benefit of STANAG 4406 is that there is an application level definition and use of precedence.
Messages were submitted to a local MTA (Message Transfer Agent) at JFC Naples, using Isode’s R14.0 M-Switch X.400 product, connected to another M-Switch X.400 at ACT, and delivering messages to a local message store using Isode’s M-Store X.400 product. All tests were done with messages flowing in one direction, with requests for delivery reports turned off. It was found that having traffic flow in both directions confused analysis.
Differentiated Services specify QoS (Quality of Service) at the IP level by use of a value referred to as the Differentiated Services Code Point (DSCP). DSCP values are associated with a connection, which means that different TCP connections must be used for each DSCP value. As the goal is to associate different DSCP values with different message precedence values, there needs to be a connection between the pair of MTAs for each precedence value where a distinction is made. Where the DSCP value is set by the application, this can only be done for packets being sent. This means that in order for return packets to have the same DSCP values as the ones being sent, both ends of the connection need to be configured to set this. Four X.400 P1 connections were configured from the JFC Naples MTA to the ACT MTA.
| Message Precedence | DSCP | Port | Connection Type |
|---|---|---|---|
| Flash | CS3 (Flash) | 5003 | Permanent |
| Immediate | CS2 (Immediate) | 5002 | Permanent |
| Priority | CS1 (Priority) | 5001 | Permanent |
| Routine | CS0 (Routine) | 5000 | On Demand |
In order to support differentiated services, a key capability of Isode’s M-Switch X.400 product is the ability to configure multiple independent connections between a pair of MTAs. Associated with each of these connections is a schedule and other control options. There are four items shown in the table above which are relevant to this setup:
- Message Precedence. The schedule controls the precedence of messages that can use the connection. This is key to the system, as it ensures messages get sent on a TCP connection associated with the message precedence.
- DSCP. The DSCP value can be set for each connection. In the tests, standard DSCP values which map to message precedence values were used. Different bindings are possible.
- Port. In the test setup, use of different port was not strictly needed as DSCP values were set by the application. However, it was useful to help network analysis. This configuration could be important in a deployment where DSCP values are controlled by the network (which is typically done based on port number). Using different ports enables the network to distinguish between messages of different priorities.
- Connection type. M-Switch X.400 can establish connections that are held open (permanent) or are opened only when there is traffic (on demand). A permanent connection reduces message latency, as messages can be sent without the need to establish a connection first.
This sophisticated configuration at the X.400 application level leads to a very simple effect at the IP level. When a message is sent, the IP packets associated with that message have an appropriate DSCP value. Once set up, the messaging application was simply used for load generation. There was no requirement to change configuration, and no need for tuning or parameter changing.
Dummy Load
A dummy load generator sent UDP packets from JFC Naples to ACT (i.e., over the same path as the messaging). The packet rate delivered 1 MBit/second which was higher than the shaped 512 kbps network bandwidth limit, so the dummy load could saturate the network. This provided an “aggressive” load, as it remained constant when packets are dropped. The DSCP value of the dummy load was selectively configured at lower, competing and higher QoS labels to generate background traffic and the impact was monitored.
Router Configuration
Differentiated Services control was applied at a single local router (SAR). It would have been too complex to attempt to analyze interactions between different policies at different routers. Changes to router configuration were key to providing effective DSCP based control. Policy choices are specific to router product, although the functions noted here are quite generic. EF traffic uses priority queuing and all other use a form of Class Based Weighted Fair queuing. The routers used were CISCO 2811 running Advanced IP services – IOS version 12.4. The router configuration is based on the following parts:
| ACL to mark incoming background dummy load packets |
|---|
| p access-list extended acl-cs1-blast |
| remark Packets Service Class – cs1 |
| permit ip host 10.10.64.31 any |
| permit ip host 10.10.64.11 any |
| ip access-list extended acl-cs2-blast |
| remark Packets Service Class – cs2 |
| permit ip host 10.10.64.40 any |
| Class definition |
|---|
| class-map match-any cmap-cs4-blast |
| match access-group name acl-cs4-blast |
| class-map match-any cmap-cs2-blast |
| match access-group name acl-cs2-blast |
| class-map match-any cmap-cs1-blast |
| match access-group name acl-cs1-blast |
| Policy definition – Input marking the dummy load: |
|---|
| policy-map blast |
| class cmap-cs1-blast |
| set dscp cs1 |
| class cmap-cs2-blast |
| set dscp cs2 |
| Policy definition – Output child policy (queue definition and dropping policy) |
| policy-map WAN-out-sub |
| class class-default |
| bandwidth 512 |
| random-detect dscp-based |
| random-detect dscp 0 15 20 10 |
| random-detect dscp 8 30 40 10 |
| random-detect dscp 16 40 60 10 |
| random-detect dscp 46 60 80 10 |
| random-detect dscp 48 80 100 10 |
| Policy definition – Output parent policy ( shaper ) |
| policy-map WAN-out |
| class class-default |
| shape average 512000 512000 |
| Applying the policy – Input interface |
|---|
| interface FastEthernet0/1 |
| description LAN-JFCNAPLES |
| ip address 10.10.64.1 255.255.255.0 |
| no ip redirects |
| no ip proxy-arp |
| ip pim sparse-dense-mode |
| ip ospf message-digest-key 10 md5 7 011D01074819030B |
| ip ospf priority 255 |
| load-interval 30 |
| duplex full |
| speed 100 |
| service-policy input blast |
| Applying the policy – Output interface |
| interface FastEthernet0/0 |
| description FE0-0 to WAN |
| bandwidth 512 |
| ip address 10.10.249.1 255.255.255.252 |
| no ip redirects |
| no ip proxy-arp |
| load-interval 30 |
| duplex half |
| speed 10 |
| no cdp enable |
| max-reserved-bandwidth 100 |
| service-policy output WAN-out |
Tests
Round 1
In the initial set of tests, the router had a default configuration with no queuing, shaping or background loading, and provided JFC Naples with access to 2 MBit/second throughput. The first set of tests looked at message throughput with different size of messages. One message was sent at a time, so the numbers shown give the transfer rate for one message with no other network traffic. The best result is shown over a small number of tests. For 1kByte messages, there was quite significant variation in transfer time. For larger messages, results were very similar;
| Size | Transfer Time (seconds) | Throughput (kBits/second) |
|---|---|---|
| 1k Byte | .031 | 258 |
| 10 kByte | .109 | 734 |
| 100 kByte | 1.719 | 465 |
| 1 MByte | 15.078 | 533 |
| 10 MByte | 165.032 | 484 |
It can be seen that larger messages get around 500 kBits/second throughput. 1kByte messages could not go so fast. 10kByte messages went faster.
For some reason, a single transfer would stabilize at about 25% of the available bandwidth. This was not an application limit, and it is suspected that the router is in some way limiting the amount of bandwidth given to a single long lived TCP connection.
For single message transfer, the DSCP setting did not appear to affect throughput at all (which is what would be expected).
In order to test message against message interaction, it was important to get M-Switch to transfer multiple messages together. This is not easy, as M-Switch’s intelligent queuing came into play:
- If messages of different precedence values were queued, no attempt is made to transfer the lower precedence messages until the higher precedence messages had been sent.
- For messages of the same precedence, a second connection would not be opened immediately (i.e., you only get multiple connections at the same precedence when the queue size increases).
These queue management approaches are good, but made test traffic generation hard. The approach that was used was to send a low precedence messages, followed by a higher precedence message. In this scenario, M-Switch continues to send the lower precedence message and immediately starts to send the higher precedence message. Because of the time taken to send messages from a GUI, only the larger messages were useful for this testing. Tests were done for multiple 10 MBbyte messages in parallel, and each group in the following table shows messages sent at the same time. Note that overlap is not perfect, due to the time taken to start off the subsequent messages.
| Precedence | DSCP | Transfer Time (secs) | Throughput (kBit/sec) |
|---|---|---|---|
| Routine | CSO | 177.672 | 450 |
| Flash | CS3 | 177.297 | 451 |
| Precedence | DSCP | Transfer Time (secs) | Throughput (kBit/sec) |
|---|---|---|---|
| Routine | CSO | 190.329 | 420 |
| Priority | CS1 | 216.547 | 369 |
| Flash | CS3 | 184.812 | 433 |
| Precedence | DSCP | Transfer Time (secs) | Throughput (kBit/sec) |
|---|---|---|---|
| Routine | CSO | 193.616 | 413 |
| Priority | CS1 | 211.031 | 379 |
| Immediate | CS2 | 172.594 | 464 |
| Flash | CS3 | 189.43 | 422 |
| Precedence | DSCP | Transfer Time (secs) | Throughput (kBit/sec) |
|---|---|---|---|
| Routine | CSO | 202.593 | 395 |
| Priority | CS1 | 223.062 | 359 |
| Immediate | CS2 | 240.172 | 333 |
| Flash | CS3 | 247.484 | 324 |
| Override | CS4 | 213.078 | 375 |
The key point on these test results is that as extra messages are added, they get bandwidth that was not being made available to the other messages. This means that although there is some slowdown, the reduction in performance is not that great. This gives a poor test scenario for looking at the effect of DSCP values. The default router settings did not appear to give any benefit to higher precedence messages.
Round 2
In the second round of tests, a key change was made to the router configuration to restrict (shape) outbound data rate to 512 kBit/second. It was decided to focus on larger messages only, as they provided traffic for long enough to monitor externally. Baseline tests were repeated on an unloaded network.
| Size | Transfer Time (seconds) | Throughput (kBits/second) |
|---|---|---|
| 1 MByte | 22.25 | 359 |
| 10 MByte | 212.969 | 376 |
Monitoring at the IP level suggested a network throughput which was just over 400 kBit/second. This is higher than the application value, do to overhead of the intermediate protocol layers. A single message appeared to give reasonable utilization of the available bandwidth. The dummy load was measured, and it was able to get close to 500 kBit/second utilization.
The router was set up with three queues, and the following bandwidth reservation, using queues for two specific DSCPs, each with a bandwidth reservation, that guaranteed a percentage of the overall bandwidth for the queue.
| Router Queue | DSCP | Reservation |
|---|---|---|
| 1 | CS1 | 50% |
| 2 | CS2 | 50% |
| 3 | Other | No reservation |
A large message was sent at CS0 priority, followed by a shorter message at CS3 that was transferred during the transfer of the larger message. The following table shows the transfer time for these two messages. These DSCP values were chosen so that a router queue was shared.
| Precedence | Size | DSCP | Transfer Time (secs) | Throughput (kBit/sec) | % Base Rate |
|---|---|---|---|---|---|
| Routine | 10 MByte | CSO | 229.18 | 349 | 93% |
| Flash | 1 MByte | CS3 | 25.84 | 309 | 86% |
The Flash (CS3) message was able to be transferred at a rate that was only slightly less than the rate in the reference tests, and thus obtained the majority of the bandwidth that was available during the transfer. There was some reduction of throughput relative to the base rate, which suggests that although the router strongly favored the higher priority traffic, that the fairness approach did not throttle back the CS0 traffic completely. This fairness is probably desirable.
To achieve the high throughput for the CS3 message, transfer of the Routine (CS0) message was throttled back while the CS3 message was being transferred. Overall transfer rate for the CS0 message was reduced as a consequence. This test shows the DSCP setting working to allocate resources in favor of the higher precedence message. If packets had been dropped evenly during the 25 seconds that the CS3 message was being transferred, this would have led to bandwidth being shared evenly between the two messages, and the throughput would have been somewhat less that 250 kBit /sec (half of the available bandwidth).
This was done with a single router queue, and ordered dropping.
Background traffic was sent at the CS1 level, and various messages were sent. Each of the following messages was sent on its own, with the background traffic.
| Precedence | DSCP | Size | Transfer Time (secs) | Throughput (kBit/sec) | % Base Rate |
|---|---|---|---|---|---|
| Immediate | CS2 | 1 MByte | 39.8 | 201> | 55% |
| Immediate | CS2 | 10 MByte | 427.828 | 187 | 49% |
| Routine | CS0 | 1 MByte | 2964 | 3 | 0.8% |
| Routine | CS0 | 10 kByte | 32.953 | 2.4 | |
| Priority | CS1 | 10 kByte | More than 3 mins | Less than 0.3 |
It can be seen for the CS2 traffic, that the bandwidth reservation worked, and that the message received half of the available bandwidth. CS0 traffic, which used a separate queue with no bandwidth reservation got low throughput. CS1 traffic, which shared a router queue with the dummy load got almost no bandwidth.
At this point the router was reconfigured to use a single queue with ordered dropping. The baseline tests were re-run:
| Size | Transfer Time (seconds) | Throughput (kBits/second) |
|---|---|---|
| 1 MByte | 17.2 | 465 |
| 10 MByte | 175.25 | 456 |
The single queue gave better throughput & the reasons for this are unclear.
A test was run with CS1 dummy load, and transferring a 1MByte CS2 message:
| Precedence | DSCP | Transfer Time | Throughput (kBit/sec) |
|---|---|---|---|
| Immediate | CS2 | More than 9 min 40 sec | Less than 13 |
The dummy load was so aggressive, that it effectively blocked out the test message. Although the queue was preferentially dropping the CS1 packets, sufficient CS2 packets were dropped to cause the TCP to slow right down.
The router configuration was then changed to use standard CISCO dropping with a varying queue depth. The goal of this was to have the router drop the lower precedence packets more aggressively. The previous test was then repeated:
| Precedence | DSCP | Transfer Time (secs) | Throughput (kBit/sec) |
|---|---|---|---|
| Immediate | CS2 | 136.078 | 59 |
This was a substantial improvement over the previous ordered dropping settings, but the aggressive lower priority traffic still had a major impact on the less aggressive higher precedence traffic. This suggests that for traffic of such differing characteristics, simple ordered dropping approaches with standard Cisco settings do not work as a mechanism to give priority for higher precedence traffic. Ordered dropping may be useful in this scenario if a more aggressive dropping strategy was used.
Messaging Analysis
The key questions to be answered at the messaging level were set out in the Isode whitepaper [Sending FLASH Messages Quickly: Techniques for Low Latency Message Switching and Precedence Handling]. This paper made a number of points relevant to these measurements.
- That in practice, automatic message pre-emption (stopping transfer of a lower priority when a higher priority one arrives) would not be useful in most situations. This was strongly borne out during the testing. It proved difficult to get M-Switch X.400 to send messages of different precedence in parallel. Also, performance issues were always in the context of other traffic, and it seems clear that the major issue will not be a switch interacting with its own traffic.
- In situations where messages of different precedence are being transferred, differentiated services can be used to ensure that the higher precedence message gets as much bandwidth as it can use and is not limited by the lower precedence message. The third table in “round 2” shows that this works in practice.
We conclude that use of Differentiated Services can work well in support of messaging applications with variable message precedence, where there is a desire to give priority to higher precedence messages and network capacity is limited.
Router Analysis
The messaging setup gives a clear cut network behavior, and a simple “it works” conclusion can be drawn. A number of points came out of the work:
- There are lots of ways to adjust router settings, and working out optimal settings is complex and needs to take many things into account.
- Different router queues should be used for different types of traffic. It was clearly a poor choice to mix TCP based messaging traffic with the UDP dummy load. Similarly, messaging should not share a queue with voice or streaming video.
- For similar types of traffic, a single queue can be used, and DSCP can be used effectively to distinguish between traffic of different precedence. There is no need to have a queue for each traffic class.
- If you wish to distinguish traffic by precedence, the queue drop algorithm details will impact how strongly you differentiate. This will need to be considered carefully in a deployment.
- Bandwidth reservation is a good approach to protect TCP traffic against more aggressive traffic, such as video.
- Fairness algorithms can be helpful, but will prevent higher precedence applications from getting all of the bandwidth. In general, it seems desirable to let some traffic through, and not allow anything to dominate completely.
- Better network analysis tools that can analyze based on DSCP values would be very helpful.
Whitepaper Licensing
Isode whitepapers are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License
![]()
Browse Related Whitepapers
