Performance Measurements of Application using IP over HF Radio
This paper sets out the results of measurements made when running applications and layer protocols to support applications over IP via HF Radio using STANAG 5066. The goal of this work was to get a quantitative measure of the performance impact of using applications running over IP over HF Radio in comparison with applications running directly over specialized HF Radio protocols. This paper concludes that the performance impact of using IP is massive, with small message latency increase from at typical value of 6-20 seconds using applications optimized for HF to a smallest measured value of 89 seconds when using IP.
Most measurements show substantial throughput performance hit: often 3-8 times slower, and up to 50 times slower. As a consequence, Isode strongly recommends that IP is not used over HF Radio for mission critical applications, except in certain very specialized circumstances.
HF as an IP Subnet vs Applications Optimized for HF
The following diagram shows how HF Radio could be deployed as an IP Subnet bearer. This is a standard approach to integrating different network technologies, and use of IP as the single common layer that separates application from network.

This architecture has a number of major benefits. In particular:
- Standard application protocols can be used, with the network technology choice transparent to the end user.
- Where multiple network technologies are used, switchover and failover between the technologies is handled by network switching and is transparent to the user and application.

An alternative approach is that an application proxy or relay is used, and specialized protocols are used directly over the HF radio. This approach has a number of benefits and disadvantages relative to using HF Radio as an IP subnet bearer.
This paper looks at one key aspect of the trade-off: relative performance. Given the inherently poor performance of HF Radio (low bandwidth and high error rate), it is important that the architecture chosen makes efficient use of the underlying network.
Running IP over HF using STANAG 5066

STANAG 5066 provides a standardized separation between application and HF Radio data link layer, described in the Isode whitepaper [STANAG 5066: The Standard for Data Applications over HF Radio]. STANAG 5066 defines (and mandates) in Annex F support of IP running over STANAG 5066. The architecture for this is shown above. Note that IP is not an end to end protocol, and is used in conjunction with end to end layer protocols. The most common are:
- TCP (Transmission Control Protocol). This provides a reliable data stream over IP, and is used by the vast majority of Internet application protocols.
- UDP (User Datagram Protocol). This is used for some specialized applications, including some key infrastructure protocols; in particular DNS (Domain Name System).
- RTP (Real Time Protocol). This provides an unreliable streaming protocol for voice video and other streaming protocols. It is used for almost all Internet multimedia data transfer. RTP is generally used in conjunction with setup protocols such as SIP and JINGLE that run over TCP.
The diagram above shows how IP over STANAG 5066 would fit into the overall architecture. STANAG 5066 is used for the link communication between a pair of IP system. This will usually be between a pair of routers (intermediate systems) but may also be with a host (end system). STANAG 5066 Annex F defines the details of how this works.

STANAG 5066 is deployed using the SIS (Subnet Interface Service) protocol, which runs over TCP/IP. This will decouple the STANAG 5066 application (in this case the IP Service) from the STANAG 5066 server and associated modem/radio subsystem. The diagram above shows how the SIS protocol and STANAG 5066 Server fit with an IP Router.
IP can also be run over STANAG 4538. We would expect this to lead to results very similar to those obtained here for STANAG 5066 ARQ mode. It would be useful to confirm this by measurement.
Previous Supporting Measurements
The measurements of this paper need to be interpreted in the context of two earlier sets of measurements made by Isode, which are referenced in the following text as:
“The STANAG 5066 Performance Paper” – STANAG 5066 Performance Measurements over HF Radio gives a set of base measurements as to how STANAG 5066 performs. It only makes sense to consider the performance of protocols running over STANAG 5066 in the context of the characteristics of the service provided by STANAG 5066 to the application.
“The HF Messaging Performance Paper” – Measuring Performance of Messaging Protocols for HF Radio gives measurements of messaging protocols designed to work over STANAG 5066. These measurements give a base line for comparing the performance of messaging applications running over IP. It is recommended to read both of these papers carefully before reading this one.
Test Setup
The test setup used here is essentially the same as the one used in the other Performance Papers. We used RM6 HF Modems from RapidM and the associated STANAG 5066 Servers, connected back to back with an audio link.
This setup should give “perfect transfer”. A software bug (now fixed) led to a small level of packet loss. This small data loss seems realistic, and showed a number of interesting characteristics during tests.

The diagram above shows the IP and STANAG 5066 setup used for all of the tests. The IP Routers used for the tests are Red Hat Linux servers – the data volumes are low, and so there is no need to use special purpose hardware or operating system. The STANAG 5066 IP Client for Linux was developed by NATO NC3A, who provided the software for these tests.
The applications used in the various tests then simply connect to the routers using IP, and this provides the applications with an IP path that is switched over HF Radio.
UDP Tests
The first set of tests uses UDP (User Datagram Protocol). UDP is a simple transport layer protocol that effectively provides the application with direct access to the IP service. It provides an unreliable service, as IP is unreliable (i.e., routers and network components may discard IP packets). UDP measurements give a clear insight into the (raw) performance of IP over STANAG 5066.
Testing Framework and Analysis

The test framework consists of a UDP generator that sends out UDP datagrams and a peer test analyser. The test generator sends out packets at size and rate specified for the test. Each packet is numbered, and includes a time stamp. The analyser records which packets are received (and by implication which packets are lost) and the delay.
UDP Measurements
IP over STANAG 5066 uses a direct mapping of IP packets onto the STANAG 5066 Unit Data service. Mapping may by ARQ (reliable) or non-ARQ (unreliable). The STANAG 5066 Performance paper made direct measurements of ARQ and non-ARQ transmission of Unit Data. The first set of UDP performance tests was seeking to measure throughput performance, and measurements equivalent to the STANAG 5066 tests were made. The UDP tests will add an overhead of 28 bytes for each datagram sent (8 bytes from UDP and 20 bytes from IPv4). This overhead can be calculated and deducted, so that a direct comparison with the STANAG 5066 results can be made. Packets were sent at a rate that of 100% of what the link can cope with, and so some packet loss occurred in the tests. This happens when the STANAG 5066 Server flow controls the IP Client, which will drop packets that cannot be sent. All tests were done in ARQ mode. It was seen as more important to carefully investigate characteristics of ARQ mode, as TCP could not be made to work when non-ARQ mode was used. The subsequent ACP 142 tests use IP over STANAG 5066 in non-ARQ mode.
The following table shows for various combinations of line speed and PDU Size (the user data provided to UDP) the throughput, and the percentage overhead (comparing throughput to line speed). The IP/UDP overhead shown is a calculated value, with the remaining overhead assigned to STANAG 5066. Where equivalent STANAG 5066 measurements were made in the STANAG 5066 performance paper, the measured overhead is shown.
| Line Speed | PDU Size | Throughput (bits/sec) | Total Overhead | IP/UDP Overhead | S5066 Overhead | S5066 Overhead (comparison) |
|---|---|---|---|---|---|---|
| 9600 | 2048 | 7330 | 24% | 1% | 22% | 17% |
| 9600 | 1500 | 5859 | 39% | 2% | 37% | |
| 9600 | 1024 | 6639 | 31% | 3% | 28% | |
| 9600 | 512 | 3898 | 59% | 5% | 54% | |
| 9600 | 256 | 2016 | 79% | 10% | 69% | |
| 9600 | 128 | 1010 | 89% | 18% | 72% | |
| 9600 | 64 | 506 | 95% | 30% | 64% | |
| 1200 | 2048 | 1027 | 14% | 1% | 13% | 10% |
| 1200 | 1024 | 966 | 20% | 3% | 17% | 11% |
| 1200 | 512 | 900 | 25% | 5% | 20% | 12% |
| 1200 | 256 | 896 | 25% | 10% | 15% | 15% |
| 1200 | 128 | 766 | 36% | 18% | 18% | 32% |
| 1200 | 64 | 483 | 60% | 30% | 29% | 67% |
| 75 | 1500 | 4 | 95% | 2% | 93% | 13% |
| 75 | 1024 | 8 | 90% | 3% | 87% | |
| 75 | 512 | 42 | 44% | 5% | 39% | |
| 75 | 256 | 49 | 35% | 10% | 25% | |
| 75 | 128 | 40 | 47% | 18% | 29% | |
| 75 | 64 | 32 | 58% | 30% | 27% |
Observations on this data:
- For large PDUs at 1200 and 9600, reasonable line utilization is achieved.
- The measured STANAG 5066 overhead is somewhat higher than that measured directly. This difference was unexpected and unexplained. It is not particularly large.
- As PDU size decreases at 1200, overhead increases, broadly in line with the direct STANAG 5066 measurements. It degrades more strongly for medium sized packets. For very small packets, the IP performance does not degrade as much as would have been predicted from the STANAG 5066 measurements. This is unexplained, and assumed due to STANAG 5066 interaction with packets of varying sizes.
- At 9600, performance drops much more dramatically as packet size drops. The value at 1500 is anomalously low.
- The performance at 75 bits per second for large packets is very much poorer than would be expected from direct STANAG 5066 measurements. We were not able to get any useful measurements for 2048 bytes. We have no idea as to why this might be. As PDU size is decreased, performance increases, and performance for a small PDUs is in line with what might be expected.
A second set of tests was made to look at latency for different network loading. These tests were done at 1200 bits per second with a PDU size of 512 bytes.
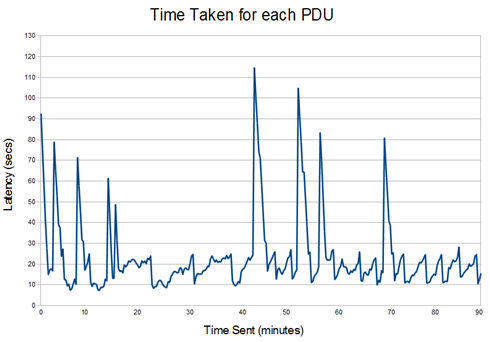
The applied load (70%) in this first graph is at a level which can get through without loss. Traffic settles to give a latency ranging broadly between 20-30 seconds. The sawtooth interval is about 30 secs, reflecting STANAG 5066 transmissions and turnaround of about this time. The larger spikes correspond to data loss. When this happens, the STANAG 5066 will retransmit. This gives a delay, because the retransmission will come after two more turnarounds. Because packets are delivered in order, this delay will also impact subsequent UDP datagrams. The double spike to the right is probably caused by the interaction of two data losses and associated retransmissions.
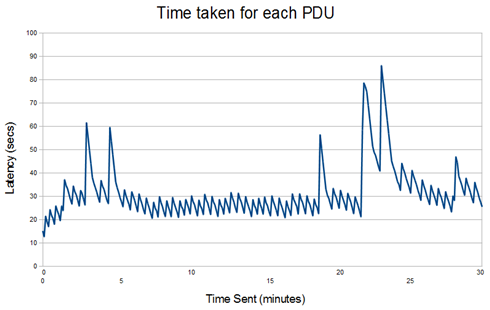
The second graph is for 20% loading (which should be easy to handle). The pattern is similar to 70% loading, but with a reduced typical latency time in the region of 10-20 seconds.
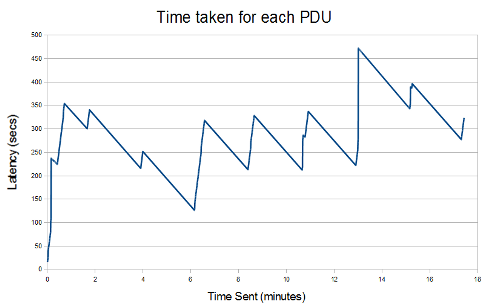
The final test had an applied load of 700%, so most UDP datagrams sent would be dropped off the back of the IP queue. After an initial build up, latency varies in the range 150-450 seconds, with a sawtooth pattern caused by the interaction of the IP queue, STANAG 5066 behaviour, and occasional data loss. The sawtooth spikes occur at approximately two minute intervals, which is in line with the 127.5 second STANAG 5066 maximum transmit time.
Analysis
Apart from the anomalous behavior with large PDUs at 75 bits per second, IP (and UDP) performance over STANAG 5066 is broadly in line with what would be expected from STANAG 5066 measurements. The overhead is somewhat higher than a theoretical calculation would suggest, but the difference is not large. At the IP level, performance is reasonable.
The delay characteristics are interesting, particularly as load increases. Understanding these characteristics will be helpful for analyzing the performance of applications and protocol layers running over IP over HF.
Application over UDP (ACP 142)
ACP 142 is a protocol designed to operate over HF Radio, and can use either STANAG 5066 UDOP (Unreliable Datagram Oriented Protocol) or UDP.
ACP 142 Architecture

Isode’s M-Switch product supports a number of options for ACP 142 based messaging shown above. The left hand diagram shows the options for operation over STANAG 5066. The HF Messaging Performance whitepaper gives performance measurements for this stack and also describes how tests were done.
The right hand diagram shows operation over IP. Note that IP is not end to end, so the application should not be considered as running over IP over STANAG 5066. Rather, IP will run over HF for one of the subnets in the end to end communication.
ACP 142 Measurements

The diagram above shows how ACP 142 works with STANAG 5066 when operating over UDP/IP. There is no direct connection from the application to STANAG 5066 – it connects via an IP Router.
| Transfer Size (bytes) | Number of Messages | Over IP | Over S5066 | Delta Utilisation | |||
|---|---|---|---|---|---|---|---|
| Rate (bits/sec) | Time | Utilisation | Time | Utilisation | |||
| 351 | 1 | 800 | 8 | 29% | 6 | 39% | 10% |
| 351 | 10 | 800 | 65 | 36% | 55 | 43% | 7% |
| 351 | 100 | 800 | 498 | 47% | 407 | 57% | 11% |
| 1448 | 1 | 800 | 18 | 54% | 14 | 69% | 15% |
| 1448 | 10 | 400 | 333 | 29% | 142 | 68% | 39% |
| 1448 | 100 | 400 | 3262 | 30% | 1235 | 78% | 49% |
| 10825 | 1 | 400 | 219 | 33% | 101 | 71% | 38% |
| 10825 | 10 | 400 | 2207 | 33% | 880 | 82% | 49% |
| 104421 | 1 | 400 | 2316 | 30% | 840 | 83% | 53% |
These measurements give a comparison of performance over IP and over STANAG 5066. The messages have 0, 1, 10 and 100 kByte payloads. The sizes given here are the ACP 142 file sizes; analysis relative to these file sizes gives a clear measurement of ACP 142 performance over the underlying networks.
The STANAG 5066 mappings used an MTU size of 2048. The IP mappings used an MTU size of 1500 (typical LAN IP MTU size choice) and a non-ARQ mapping of IP onto STANAG 5066 (so that both sets of measurements used non-ARQ).
A key additional setting is the rate control, which controls how fast the sending system sends out IP packets. The settings of this were chosen empirically. If the setting was too high, we observed that there was packet loss due to IP packets being dropped by the STANAG 5066 IP Client. This is highly undesirable, as it will require application level requests for retransmission. We tuned the values to a level where we did not see IP packet loss. This was primarily for the longer tests. We were surprised as to how low we had to go in order to avoid IP packet loss.
For small messages the overheads using IP are small (around 10% additional overhead) and this ties with the UDP measurements. For larger messages, the performance degradation was more significant. It would almost certainly be possible to get some performance increase by very careful tuning of the rate parameter. However, if increased too far, performance will drop significantly due to retransmissions.
Analysis
Operating ACP 142 over IP over HF can give reasonable performance (10% overhead relative to direct use of STANAG 5066) in some situations, particularly where messages are small and transmissions are infrequent.
Performance will not be so good in other situations, including:
- Transfer of larger messages
- Where other nodes transmit messages at the same time
- Where the STANAG 5066 is shared with other services
- Where underlying data rate varies
Changing the rate will help to tune performance, but setting the value for complex situations will be hard, and will almost certainly impact performance in some situations. Where possible, it is clear the direct operation over STANAG 5066 is preferable to use of IP.
Other applications over UDP
There are relatively few applications built to operate over UDP. Often applications using UDP have low data volumes with infrequent traffic. This sort of application would be expected to work reasonably over HF, provided that the application is tolerant of long delays. An example application that works in this way is the Bowman situational awareness application. This uses an ARQ mapping of IP, and the application treats IP as a reliable datagram service for information update.
It would be desirable to have applications that transfer bulk data be able to adapt to transfer rate. Designing such a protocol would be very hard (perhaps impossible) because of the very long delays and turnaround times. It is much easier for applications that can make use of STANAG 5066 flow control.
TCP Tests
Why TCP is Important
TCP (Transmission Control Protocol) is used for most Internet applications. It provides reliable data stream, and is a sensible choice for any application needing reliable data transfer. Because of this, understanding the TCP interaction with HF is key to understanding application performance over HF.
How TCP Works
In order to understand the results and analysis here, it is important to have some understanding as to how TCP works. The Wikipedia article is a reasonable starting point. Key concepts (simplified):
- All the TCP data packets are carried within IP packets.
- TCP starts with a synchronous handshake.
- Data packets are sent asynchronously, and each data packet is acknowledged with an ACK.
- TCP uses a “Window” mechanism to control rate. The Window defines the amount of un-acknowledged data that a sender allows. When there is data loss (and retransmission) a sender will “close down” the window to reduce rate, on the basis that data loss is being caused by congestion on the network. When there is no data loss, a sender will gradually “open up” the window. This will lead to an optimum setting.
- A TCP sender needs to determine when to retransmit data that has not been acknowledged. This is controlled by the Retransmission Timeout (RTO). The Round Trip Time (RTT) is a key input to determining RTO, but is not the RTO. RTO will typically be determined with a complex algorithm such as Fast RTO specified in RFC 4138.
- Window size and RTO calculation are key to performance over HF.
- TCP uses IP packets up to a given size (MTU). Typical values of MTU are 500 bytes for wide area traffic and 1500 bytes for LAN traffic. These are the values used in tests.
Testing Framework

The TCP Test framework is similar to the one used for UDP testing. The test generator opens up a TCP stream, and writes data as fast as it can, waiting for operating system flow control. It includes time stamps within the data sent.
The test analyser reads data from the TCP stream. It records how long it took to establish a connection, and then arrival time of subsequent data blocks. This gives a simple measurement of throughput and latency.
TCP Measurements
In order to make the system work, the TCP was configured on the test systems to have a larger than normal number of connection attempts. This was necessary to establish the first connection to a peer. Once done, the RTT was cached, and so suitable time values were used on subsequent attempts.
Measurements were made at 9600, 1200, and 300 bits per second. We were unable to get TCP to work at 75 bits per second, which was where we made STANAG 5066 measurements. At each speed we used MTU of 500 and 1500. The following graph is typical.
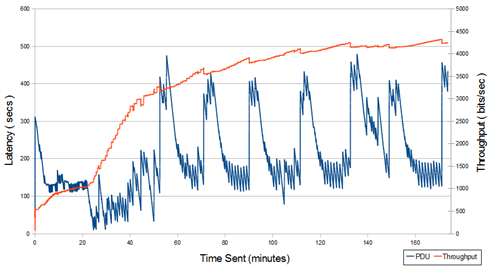
It can be seen that the average throughput rises steadily and reached a stable value. This pattern was seen for all bar one of the tests. The latency does not reach a steady state, and there is an oscillating pattern. This reflects bursty arrival of data over the test, so although throughput is optimized, the system never really reaches a stable state.
For each of the tests run, the final throughput level is measured, and the time taken to reach 50% and 80% of the maximum throughput. This is shown below.
| Link Speed | MTU Size | Throughput | Utilisation | Time to 50% (mins) | Time to 80% (mins) | First Data (secs) |
|---|---|---|---|---|---|---|
| 9600 | 500 | 4258 | 44% | 34.5 | 65.5 | 60 |
| 9600 | 1500 | 5104 | 53% | 5 | 27.5 | 12 |
| 1200 | 500 | 748 | 62% | 2.5 | 74.9 | 47 |
| 1200 | 1500 | 798 | 67% | 0 | 1.5 | 20 |
| 300 | 500 | 137 | 46% | 2.5 | 3.5 | 120 |
| 300 | 1500 | 6 | 2% | n/a | n/a | 136 |
It can be seen that for many tests it took a long time to reach stable state. This is because TCP uses “slow start”, where the window is initially small and the increased. Because of the long RTT, it takes a long time to open up the window to the optimum amount. This has most impact at higher speeds, because here the optimum window size is larger. At 300 bits/sec, the starting window size is reasonable. When MTU size is increased, the optimum window size is smaller, and so the system reaches this value more quickly. Larger MTU also appears to noticeably increase efficiency at higher data rates. At 300 bits/second the system was barely able to work with the larger MTU, but was fine with 500.
The time for first data to arrive is recorded. The differences between 500 and 1500 bytes are significant. We do not understand why this is the case. Some more graphs are shown now, to give a picture of some of the behaviors observed.
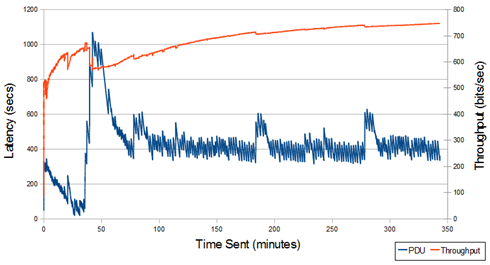
This graph shows that throughput quickly reaches a stable value. Latency varies dramatically, with a rather different pattern to the previous graph, and appears to stabilize after an hour.
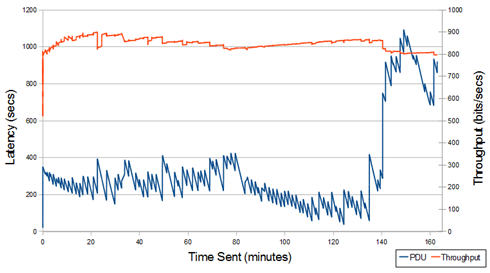
This graph appears to reach a more stable latency quickly, but after a long period of time shifts to a higher delay, so clearly there was instability.
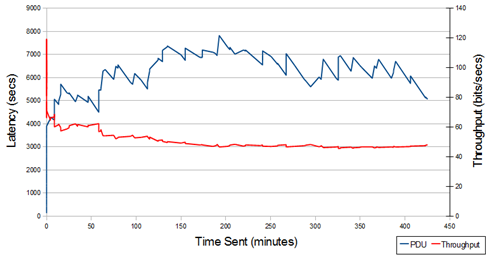
This shows the one that did not really work. Throughput started poorly and degraded (to 2%), with latency going to a very high value. It was not able to achieve a sensible use of the link, although it did work after a fashion.
Analysis
In some of the tests TCP was able to achieve reasonable throughput. However, there are a number of concerns:
- The time taken to reach useful throughput was often very slow, which we be a problem for many applications using TCP, especially those with shorter lived connections.
- The wildly varying latency (lack of stable latency) in many tests and associated bursty traffic is undesirable.
- Inability to work effectively at the low end of the HF range.
- Configurations such as 1500 MTU at 300 bits per second, that ended up working in a very inefficient manner.
We believe that the impact of the long underlying IP delays, and the variability of underlying latency dependent on load, has a complex interaction with the TCP protocol, causing some of the effects seen.
Impact of Errors and Varying Conditions
The tests were undertaken in near perfect conditions. In a real deployment, there would be variability, due to errors; varying speed of underlying links; competition with other applications; periods of no traffic. From our observations of the rather unstable nature of the interaction between TCP and HF, it seems likely that operational conditions would lead to significantly poor performance than observed here.
SMTP Tests
The next section looks at application level measurements. We use the Internet Standard SMTP (Simple Mail Transfer Protocol) which runs over TCP, and can be directly compared with protocols optimized for HF, described in the HF Messaging Performance Paper.
Testing Framework and Comparison
The messaging test framework described in the HF Messaging Performance Paper was used to measure SMTP running over TCP/IP with IP running over HF. CO-ACP 142 is used as the reference protocol here, as in the paper. The diagram above shows the testing setup for SMTP.
SMTP Measurements
| Link Speed | Message Size | Number of Messages | SMTP | Co-ACP 142 | Comparison Factors | ||
|---|---|---|---|---|---|---|---|
| Time | Utilisation | Time | Utilisation | ||||
| 9600 | 386 | 1 | 138 | 0.2% | 18 | 1.8% | 7.7 |
| 9600 | 396 | 10 | 1065 | 0.3% | 21 | 15% | 50.7 |
| 9600 | 14025 | 1 | 907 | 1.3% | 24 | 49% | 37.8 |
| 9600 | 14025 | 10 | 1201 | 9.7% | 130 | 90% | 9.2 |
| 9600 | 135604 | 1 | 832 | 13.6% | 127 | 89% | 6.6 |
| 9600 | 135604 | 10 | 6202 | 18.2% | 1182 | 96% | 5.2 |
| 1200 | 386 | 1 | 89 | 2.9% | 21 | 12% | 4.2 |
| 1200 | 386 | 10 | 436 | 5.9% | 56 | 46% | 7.8 |
| 1200 | 386 | 100 | 4388 | 5.9% | 346 | 74% | 12.7 |
| 1200 | 1867 | 1 | 125 | 10.0% | 30 | 41% | 4.2 |
| 1200 | 1867 | 10 | 818 | 15.2% | 148 | 84% | 5.5 |
| 1200 | 1867 | 100 | 6450 | 19.3% | 1182 | 105% | 5.5 |
| 1200 | 14025 | 1 | 250 | 37.4% | 97 | 96% | 2.6 |
| 1200 | 14025 | 10 | 1854 | 50.4% | 837 | 112% | 2.2 |
| 1200 | 14025 | 100 | 19013 | 49.2% | 8268 | 113% | 2.3 |
| 1200 | 135604 | 1 | 1442 | 62.7% | 796 | 114% | 1.8 |
| 1200 | 135604 | 10 | 13541 | 66.8% | 7993 | 113% | 1.7 |
| 300 | 386 | 1 | 356 | 2.9% | 30 | 34% | 11.9 |
| 300 | 386 | 10 | 1419 | 7.3% | 171 | 60% | 8.3 |
| 300 | 1867 | 1 | 246 | 20.2% | 71 | 70% | 3.5 |
| 300 | 1867 | 10 | 1664 | 29.9% | 521 | 96% | 3.2 |
| 300 | 14025 | 1 | 977 | 38.3% | 442 | 85% | 2.2 |
This table shows performance for messages of differing sizes (0, 1, 10 and 100 kByte payloads) with size of submitted message measured. Because CO-ACP 142 does compression, utilization can be over 100%. MTU size of 1500 bytes was used for 1200 and 9600 bits/sec and 500 bytes for 300 bits/sec (the best performing value was chosen for each speed). Observations:
- For many of these tests, SMTP performance was appallingly bad.
- For two tests it was relatively reasonable (70-80% overhead relative to CO-ACP 142). This is where larger messages were transferred at 1200 bits/sec, and TCP could clearly stabilize quickly to an efficient point. The 80% result had an increase from 13.25 minutes to 24 minutes, and the 70% result an increase from 133 to 225 minutes. Even the best results still have a significant impact.
- In general there was a very high overhead for small messages.
- At 9600 bits/sec, good performance was never achieved. We assume that this was because TCP was not able to reach a useful utilization.
- Overheads at 300 bits/sec were high, essentially because you can only transfer small messages.
- The high transfer time for small messages is of particular note. Short messages can be transferred in 18-20 seconds with CO-ACP 142 (or down to 6 seconds with ACP 142). The shortest message transfer with SMTP was 89 seconds.
- The 10kByte message at 300 bits/second transferred, but the SMTP connection timed out. This caused the sender to retransmit the message. This happened repeatedly – there was clearly a nasty interaction between TCP, SMTP, and HF.
Other Applications over TCP
SMTP is just one application, and other applications will have different characteristics operating over TCP. It is important to consider how applicable the results obtained here will be to other applications running over TCP.
We believe that SMTP is quite a typical Internet application, so these will be a reasonable general guideline. Things noted about SMTP:
- It is text encoded, with a reasonably efficient encoding.
- It is synchronous on startup, and then becomes broadly asynchronous (in a modern implementation, such as the one used here).
- There is no compression.
There is no reason to believe that (relative to other Internet applications) that SMTP will have particularly poor performance over HF, or that other applications will perform significantly better or worse.
Applications not using TCP or UDP
This paper has focused on TCP and UDP. The third class of applications uses RTP. Most RTP applications such as streaming video are not appropriate for HF Radio because bandwidth demands are too high. Voice can be used. VOIP (which uses RTP) might be usable if a non-ARQ IP mapping is chosen, in order to eliminate the delay spikes which arise from an ARQ mapping. Rate control would be a problem, and it would be affected by the same issues discussed in the context of ACP 142.
As HF Radio supports optimized digital voice directly, it seems to make more sense to gateway it, and use the optimized protocols over HF.
Acknowledgements
Isode would like to thank:
- RapidM for the loan of RM6 Modems and RC66 Software. Also to RapidM staff an in particular Markus van der Riet for extensive help and explanations.
- NATO NC3A for providing the STANAG 5066 IP Client software, and to help and assistance from Donald Kallgren and Maarten Gerbrands.
Conclusions
This paper has measured the performance of IP over HF Radio, looking at UDP, ACP 142, TCP and SMTP.
Use of UDP and UDP based protocols can work reasonably well in certain situations. ACP 142 could work reasonably in a lightly loaded network transferring small messages. However, this is not a general purpose protocol, and would not really fit with the HF as an IP Subnet approach. Given this, if you are using special protocols, it will generally be advantageous to use protocols that operate directly over STANAG 5066.
Measurements of SMTP and TCP are more relevant to considering the choice of general HF as an IP Subnet vs use of special protocols for HF. Link utilization with TCP can be reasonable in some situations, primarily for longer transfers operating at mid-range HF speeds. However, a number of concerns arise:
- We could not get TCP to work at the lower HF speeds at all.
- Small message latency increase from at typical value of 6-20 seconds to a smallest measured value of 89 seconds. This would seem to be a serious problem for many mission critical applications such as formal messaging or XMPP instant messaging. Low latency is often critical.
- At higher link speeds, most communications will not last for long enough to reach effective network utilization.
- Overheads for small messages are alarmingly high. Most measurements showed substantial performance hit: often 3-8 times slower, and up to 50 times slower. This is likely to apply to any protocol, and not just to SMTP.
- TCP connections typically did not reach a really stable state. Although performance often stabilized to a reasonable value, latency continued to vary dramatically with traffic flow bursty.
- In error and variable traffic situations, the problems encountered are likely to be exacerbated. We expect that an IP based system would not be robust.
- We saw clear cases of TCP and SMTP getting to very poor operational states.
Isode’s conclusion from this is that there are too many issues and problems with operation over IP for HF, to make it a generally viable operational approach. As a consequence, Isode strongly recommends that IP is not used over HF Radio for mission critical applications, except in certain very specialized circumstances.
Whitepaper Licensing
Isode whitepapers are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License
![]()
Browse Related Whitepapers
